Shipping a Job Queue System Without Reading The Source Code

Before you dive into this — this isn't how I normally ship software, and I wouldn't recommend it for most projects. It worked here because Beanstalkd's interface is a small text protocol with well-defined behaviour, which makes it straightforward to test exhaustively. A web app or anything with complex interactions is a different story entirely.
I love the job queuing system Beanstalkd – Booko’s been using it since February 6 2010 and it’s been the most reliable, simplest piece of infrastructure to deal with since then. It has queues ( although it calls them tubes ) and it has configurable job priority and delayed jobs. It has a comprehensible, small text based interface. While listening for a job, workers block, using no resources when waiting. I must have run many tens of billions of jobs through it. I’ve used Sidekiq, and it’s also great. Nice dashboard, but more work than Beanstalkd. I’ve used GoodJob and SolidQueue. I did like their concurrency controls – well, I liked them in theory – I never quite made them work as reliably as I wanted.
As much as I love Beanstalkd, I’ve always craved a few more features – and at the top of that list was unique jobs, followed closely by weighted queues.
Claude and I had a few attempts at adding weighted queues to the Ruby Beanstalkd client beaneater. It worked, but wasn’t ideal. It’d be much easier to just do this on the server. So that was our next project – Beanstalkd is written in C, a language I’ve written C before and with Claude in the terminal, I’m sure we could knock out a PR pretty quickly. And we did, and it worked. I couldn’t follow the C code though and had no desire to re-familiarise myself with the language. If I was going to (re)learn another systems language, I’d prefer it was Rust. And so. Rust then. I created a directory, copied Beanstalkd’s C code into a subdirectory and fired up Claude.
“Lets make a Rust implementation of the project Beanstalkd - its source code is in tmp/. Ensure you duplicate all the existing test cases from the C version, in this new Rust version. We’ll call it Tuber"
I tested it by using it myself in Booko development. It worked very nicely, and so it was time to add weighted queues. A small addition to the text protocol: reserve-method weighted, paired with adding a weight to the watch which defaults to 1. And it worked! Now, it was time to read the Rust source code.
But first, another feature beckoned – unique jobs. Adding idempotency to the other queuing systems I’ve used requires mirroring state in a database or key-value store, which is fragile and fraught. If you pay for Sidekiq Pro, you get unique jobs, but I don’t have the budget for that. Instead, I added a tag to the put command: idp:abc which means the tube won’t accept another job with that key. Simple! Then I added a cooldown: idp:abc:60 . Concurrency controls came next with a new tag: con:my-api:2 means only two jobs can be reserved with that key at once. After a conversation with a colleague about fan-in/fan-out, job groups came next with grp:my-group and aft:my-group to chain dependencies.
Each feature followed the same pattern – small composable tags on the existing text protocol. Completely backwards compatible. So - where are we now? Weighted queues, unique jobs with cooldown, concurrency controls, job groups and after-job dependencies. To finish off, I added batch-reserve, batch-delete, queue-flushing. We added a subcommand to tuber: work will execute the job body in the shell so you can queue up all your ffmpegs in one hit and run them one ( or -j X ) at a time. Finally, a Prometheus endpoint. And tests, many, many tests and then fuzzed it until it stopped breaking.
Now we’re proper finished, it’s time to read the source code. Why am I reading the source code? To learn Rust or check that there are no bugs in Tuber?
I wrote what I consider to be the best stand-alone job queue system available ( MIT licensed! ) with comprehensive tests, which works very well and (so far ) is bug free (narrator: It wasn’t bug free. ) – but I’m yet to read, learn or write any Rust. And honestly, I don’t really want to.
What does this mean for the modern AI augmented developer? Is it reasonable to use and release code I haven’t ( and can’t! ) read or write? If you asked me a month ago, the answer would have been a clear No - you must understand the software you .... write?... release? It’s a minimum standard. Right? ...Right?
The Beanstalkd protocol though, is text based and tiny - 22 commands. Tuber adds 7 new commands plus the idp/con/grp/aft tags and the tube weights. And it works. Maybe it is ok to release un-read software if it’s got a tiny interface and extensive tests? A Rails app, with a non-trivial domain, ActiveRecord associations, 3rd party integrations, business logic threading through the layers would be a different beast entirely – its interface isn’t ~30 commands, it’s everything.
Claude wrote the Rust, but the decisions that make Tuber worth considering as your next job queue came from 25 years of experience writing software, building and running job queues in production that process billions of jobs. I've built those fragile idempotency systems with databases and key-value stores mirroring queue state — I know exactly how they break. Designing a small set of focused, composable, backwards compatible commands comes from that experience. Could a non-developer have built this with Claude? I’m sure anyone can now use Claude to build a job queue system in Rust, or any language, but the understanding of where the tests go, to look for corner cases and common bugs, to value backwards compatibility and composable commands comes from experience. Without that experience, they’d be building slop. I’m sure people will call this slop too, but that’s on them.
Maybe this is all just posthoc justification for being too lazy to learn Rust - but... Tuber works, is in production and I love it - it’s a perfect job system for me. I’m not going to learn Rust, at least not yet.
Addendum
I built a TUI ( Terminal User Interface ) in Rust, using Ratatui.
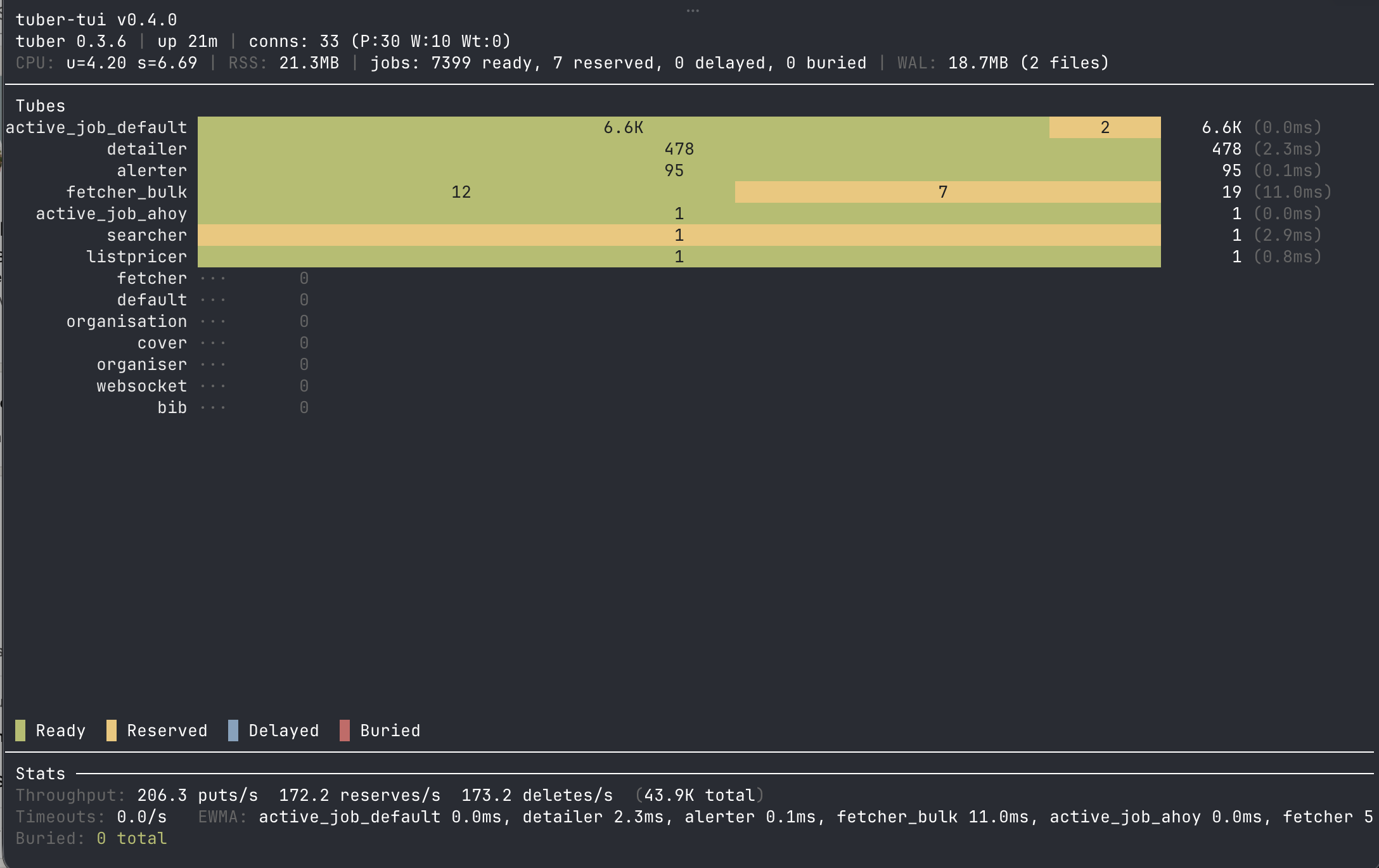
You can see Booko’s Tuber (in production) doing hundreds of puts / reserves / deletes a second. Totally smashing it.
Addendum 2
If you read the CHANGES.md file for Tuber, you’ll see it definitely was not bug free. The process of finding bugs, then passing them to Claude to reproduce with tests, then fix, has given me more, not less, confidence in releasing Tuber this way. This is not really any different to finding a bug in any software and having the reproduce, fix, release dance.